
為了確保產出良好的品質,我們大多都要模擬不同的情境下程式可能會發生的狀況,傳統不走TDD的話都要回去一行一行的翻程式碼,此舉需要花費的時間相當漫長,而且並不是很有效。
甚至寫到一半要去看covergae report有踩到哪些地方,這樣下次寫的時候才可以儘量不重複寫(尤其多人開發非常容易踩到)

如果是小範圍的程式還好,但是total lines成長到上千或是上萬行就很頭疼了...

對於這樣漫無目的的找無疑是相當大的成本,常常找一找就一整天過去了,所以就在想說有什麼更有效的方式可以處理這個問題,而目前也沒有很有效的方式去判斷哪些函式(function)哪些有用到哪些沒用到的,基本上都是靠漫無目的的人為判斷。
但這時候又要問了:難道沒有什麼更有效的方法嗎?
簡單來說,那時候的初步構想是這樣的
那時候的需求很簡單,就是我要知道哪些class有用到哪些模組。
那作法呢,首先必須要有兩個封裝的ClassA及ClassB,當ClassB需要ClassA的時候總是會用到像是use Foo\ClassA或是new ClassB之類的關鍵字做引入動作
用上面的關鍵字做regex(正則)的全文比對來找哪些有用到,這樣就可以判斷是不是有使用啦~
但是我想的實在太美好了...
如果我想知道有什麼function有用到什麼沒用到
還是得去擲筊,因為我這樣只能知道引入什麼套件啊
那除此之外還有其他作用嗎?
不好意思沒有了
所以只好硬著頭皮繼續改
一個龐大的專案經過多人維護,因為PHP「奔放」的syntax,其coding style及用的邏輯還有規則基本上都是「不可考」的狀態,像是這樣
用傳統的正則拉勢必會拉到獵奇不該出現的東西,所以正則不是一個好辦法。
到後面用上了這個東西
http://php.net/manual/en/function.token-get-all.php
這個function是早期PHP4的時候因為大量與HTML混搭,所以PHP的核心模組就把PHP Interpreter的解析用的模組另外再放出來使用,它可以很準確的判斷現在這個區塊(block)的是什麼型態。
像是上面的程式解析出來就會長的像是這樣子
array(11) {
[0] =>
array(3) {
[0] =>
int(379)
[1] =>
string(6) "<?php
"
[2] =>
int(1)
}
[1] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) "
"
[2] =>
int(2)
}
[2] =>
array(3) {
[0] =>
int(378)
[1] =>
string(23) "/**
* @use Foo\Bar
*/"
[2] =>
int(3)
}
[3] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) "
"
[2] =>
int(5)
}
[4] =>
array(3) {
[0] =>
int(361)
[1] =>
string(5) "class"
[2] =>
int(6)
}
[5] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) " "
[2] =>
int(6)
}
[6] =>
array(3) {
[0] =>
int(319)
[1] =>
string(3) "Foo"
[2] =>
int(6)
}
[7] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) "
"
[2] =>
int(6)
}
[8] =>
string(1) "{"
[9] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) "
"
[2] =>
int(7)
}
[10] =>
string(1) "}"
}
上面可以很明顯的看出來,經過token_get_all的洗禮之後,程式碼片段被拆解成一個一個的碎片(slice),每一個碎片都有一個type做定義(參考: http://php.net/manual/en/tokens.php),透過定義好的type我們可以蠻快知道哪些是註解
所以,如果我需要砍掉沒辦法受我控制的註解我可以這樣做
透過built-in的constant判斷不是註解的部分,再重新組合整份程式碼,這樣就可以用正則撈這個php file裡面引入什麼package啦
那說好的function分析呢?
前面不是提到我怎麼判斷這個php file有引入什麼package嗎?
除此之外還遇到了下面的情況:
- 我要怎麼判斷我用了private function或是protected function呢?
- 我要怎麼判斷繼承呢?
- 判斷使用很簡單,怎麼做到判斷沒用到的function?
一切的一切都是建立在良好的分析工具上面
token_get_all是很好的工具,不過很可惜的是它再怎樣都沒辦法做有結構性的檔案分析,於是嘗試了稍微專業一點的PHP Parser (https://github.com/nikic/PHP-Parser)
它跟token_get_all有什麼樣的不同呢?最大的區別是它可以把同一個statement(敘述)的歸類在一起,舉一個簡單的宣告來說好了
如果用token_get_all的話可以看到會變成像是這樣子
array(13) {
[0] =>
array(3) {
[0] =>
int(379)
[1] =>
string(6) "<?php "
[2] =>
int(1)
}
[1] =>
array(3) {
[0] =>
int(320)
[1] =>
string(4) "$foo"
[2] =>
int(1)
}
[2] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) " "
[2] =>
int(1)
}
[3] =>
string(1) "="
[4] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) " "
[2] =>
int(1)
}
[5] =>
array(3) {
[0] =>
int(305)
[1] =>
string(3) "new"
[2] =>
int(1)
}
[6] =>
array(3) {
[0] =>
int(382)
[1] =>
string(1) " "
[2] =>
int(1)
}
[7] =>
array(3) {
[0] =>
int(319)
[1] =>
string(3) "Foo"
[2] =>
int(1)
}
[8] =>
array(3) {
[0] =>
int(390)
[1] =>
string(1) "\"
[2] =>
int(1)
}
[9] =>
array(3) {
[0] =>
int(319)
[1] =>
string(3) "Bar"
[2] =>
int(1)
}
[10] =>
string(1) "("
[11] =>
string(1) ")"
[12] =>
string(1) ";"
}
那PHP Parser呢?
array(1) {
[0] =>
class PhpParser\Node\Expr\Assign#9 (3) {
public $var =>
class PhpParser\Node\Expr\Variable#2 (2) {
public $name =>
string(3) "foo"
protected $attributes =>
array(2) {
...
}
}
public $expr =>
class PhpParser\Node\Expr\New_#8 (3) {
public $class =>
class PhpParser\Node\Name#7 (2) {
...
}
public $args =>
array(0) {
...
}
protected $attributes =>
array(2) {
...
}
}
protected $attributes =>
array(2) {
'startLine' =>
int(1)
'endLine' =>
int(1)
}
}
}
差異在於token_get_all是逐字分析,所以會需要做iterator做判斷,比較麻煩而且容易出錯;可是PHP Parser的話則是採用一句statement判斷,所以識別上更容易判斷這是同一段code。
關於PHP Parser的用法 - 怎麼拉出我要的function呢
一般而言一個class裡面會由很多function組成,大概像是這樣的感覺
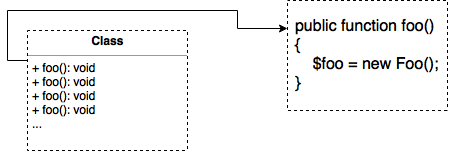
每一個class底下的function都形成一個封閉的空間,像是$foo的話可以在其他地方使用嗎?不行,所以我們的目標很明確了,要把所有的class底下的function拉出來做分析
像是Example.php
拆開之後會變成像是這樣
接著就是解開單一個function就好了喔!
幾個需要特別注意的東西
PHP裡面有幾個關鍵字比較特殊一點,它們分別為this、parent、self、static,它們的關係可以簡單畫成下面這張圖
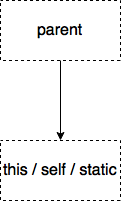
只有parent獨立出來(只能拉extends),其他的繼承parent又可以算是自己的function,這裡都需要特別處理,譬如this可以拉到parent及自己,但是parent只能拉到自己類似這些情境。
