
各位讀者好,這次想講的是比較家喻戶曉的Redis,那說到Redis就不得不提到NoSQL的歷史啦~~~再後面會提到一些Redis的特性及作用,還會舉個常見的例子來做介紹,還望各位看官不會嫌棄 😄
前言
想必很多人都會有「大量/巨量資料處理」或是「快取」上面的需求,但是傳統的DB普遍上效能低落,而且隨著資料量以及關聯的遞增,DB的搜尋效率會越低,後面的速度甚至會呈現等比遞減。
一直到了1998年後,Carlo Strozzi提出了NoSQL(No SQL)的模型,當時的NoSQL是一種不需要SQL語句來執行相關的搜尋語法的方式,並沒有實質上接近現代的NoSQL。
2009年之後,NoSQL才重新在亞特蘭大的no:sql(east)被解釋為Not only SQL,從此之後開啟了大NoSQL時代。
什麼是Redis,它跟傳統的資料庫差在哪裡?
Redis簡單來說就是NoSQL的一個分支(不然前言也不需要提NoSQL了),值的組成主要是由key-value組成,也就是一個資料對應一個唯一的key值,換句話說,不管我現在是給數字、字串或一些雜七雜八的型態的資料,我就是只能有一個key去對應我的資料。
而傳統的DB的組成是由table-column-value形成一種三階層架構,在二維空間上傳統DB會呈現一個2D平面;Redis的處理方式則是將table-column的階層統一由key解決
嗯?你說這樣講沒什麼感覺嗎?
Redis在處理上面因為都由key-value組合而成,所以可以直接放在記憶體內處理,像是程式語言的陣列一般:
foo['key1'] = 'value1';
foo['key2'] = 'value2';
foo['key3'] = 'value3';
foo['key4'] = 'value4';
我們可以想像Redis是很多個非常巨大的資料陣列,分別有各自不同的編號(預設上,Redis有著編號0~15的資料空間),每個資料陣列巨大的程度無法直接估計,而陣列裡面有許多key,每一個key都有自己對應的值。
此外,歸功於Redis本身是一個很大的陣列空間,所以儲存速度也快了非常多,下面這張圖是與MySQL對照,一次能處理的資料量:
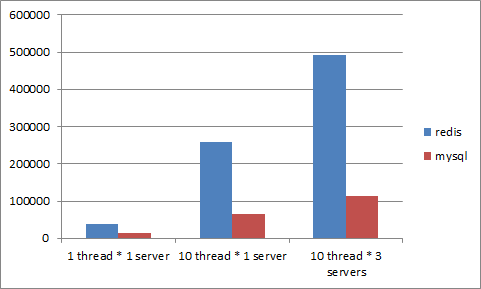
從圖上我們可以清楚的知道,MySQL需要對資料做分頁,所以越多的資料進來,需要分頁的速度就相對緩慢,資料處理速度會呈現等比遞減,不會因為處理的核心多寡資料就可以處理的比較快;而Redis不一樣,「一般而言」Redis沒有分頁的概念,反之是直接對記憶體做存取,所以不會因為資料量而降低速度,越多核心處理資料就會得到對應的提升。
綜上所述,Redis實務上更適合拿來做短期且高發散的儲存媒介。
來點有感的
那Redis支援什麼樣的資料型態呢?怎麼使用?
至目前(3.2.3)的版本,Redis支援以下幾種資料型態:
- Strings
- Hashes
- Lists
- Sets
- Sorted Sets
- Geo
- HyperLogLog
原則上Redis支援上面幾種格式,基本上所有的類型(data type)都圍繞著Strings(字串)、Hashes(相當於物件,有key)及Sets(相當於陣列,無key)所組成。
舉一個簡單的例子來說:Sets跟Sorted Sets有關係,List跟Sets也有關係。不同型態命名差異只是有序及無序的差別。
其中Sets、Geo以及儲存Redis的任何「key」都屬於「無序」的排序,排序的順序不能做為參考(造成的原因主要是因為要給記憶體存取所以這樣設計),所以如果有針對需要「時間排序」的前提下,使用Redis就需要格外的小心。
實戰篇
(指令的用法都可以在官方說明找到)
我該怎麼定義我的key呢?
redis的key的命名方式我建議可以參考這篇,當然您也可以用您喜歡的命名方式,畢竟實務上沒有限制redis必須要怎樣命名)
常理來說,都會依循這樣的命名方式,有些專案會在key上面加上狀態(state)區別(如果有的話):
{prefix}:{type}:{id}:{field}
Redis都會先給一個namspace作為prefix,可能是該專案可能是使用者定義好的名稱,中間如果有需要區隔都是以「:」作為區隔方式,拿Resque這個專案來說好了:
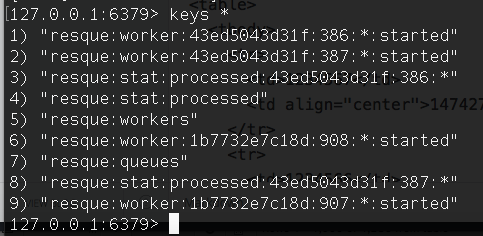
這裡我們可以很清楚的看到,Resque是以resque作為prefix,這樣在使用同一個Redis DB的時候,就不容易與其他的資料混淆。
這是其中一個keyresque:stat:processed:43ed5043d31f:387:*,把組成結構拆開來看的話:

這張表格可以清楚的反映出除了作為prefix的resque以外,另外就是描述內容(type)的stat,processed是用來敘述stat的狀態,接著是43ed5043d31f:387,作為該stat特有的id,最後則是Resque需要執行的field。
一個比較糟但不是太糟的使用實例
假設我今天要新增一個快取(cache)資料,這個可能是該使用者最後使用的時間,user的編號(member id)可能是1234567、1234566、1234565
為了方便存取,我這裡會希望用一個hash做統一控管,那我可能會使用像是這樣的指令
hset project:member:timestamp 1234567 1474272114
hset project:member:timestamp 1234566 1474272113
hset project:member:timestamp 1234565 1474272115
產生出來的Hash結構會長的像這樣:
| 1234567 | 1474272114 |
| 1234566 | 1474272113 |
| 1234565 | 1474272115 |
從上面的結構圖可以蠻清楚的知道我hash key是我的使用者的ID,而hash value則是最後的使用時間。
某天問題來了:我怎麼知道最後存取的時間呢?
由於將所有的時間都儲存在同一個hash裡面,所以勢必得將所有的值都拿出來再加以排序,寫成程式語言的話我想會像是這樣子:
redis.hvals('project:member:timestamp', function(err, res) {
// do something here
});
在這裡HVALS的用途是將HASH裡面的值全部拉出來,或許10筆資料可以、100筆也可以、1000筆也可以... 那有天我們的資料來到百萬等級呢?根據不同的語言有不同的結論,每種腳本語言能承受的陣列大小不一,如下表:
| javascript | 4294967295 |
| java | 2147483642 |
| php | 2097152(default) |
| python | 536870912 |
從上面可以清楚的看到,只有javascript能達到Redis設計的理論值,其他的從百萬級的資料過後,我們這樣的用法就會開始有問題了,甚至會吃掉系統大部分的資源。
那麼,可以怎麼做呢?來看看比較好的使用方式吧!
因為Redis在預設上是無序的,所以Redis有設計一個SORT來幫助排序:
SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern ...]] [ASC|DESC] [ALPHA] [STORE destination]
有人可能會說,那我還是沒頭緒怎麼做啊!
官方這裡給了比較詳細的說明
SORT mylist BY weight_*->fieldname GET object_*->filename
The string -> is used to separate the key name from the hash field name. The key is substituted as documented above, and the hash stored at the resulting key is accessed to retrieve the specified hash field.
從上面的說明來看,需要用「已知」的key值去做排序,但是我們保存資料的hash key值實際上為未知,只能去撈了表之後才能知道有沒有這筆資料,所以我們這裡需要一個方法去維護key值(這裡通常是一個list),並且我需要一個確切排序的欄位(retrieve the specified hash field)。所以整理過後的資料變成這樣:
project:member
| 1234567 |
| 1234566 |
| 1234565 |
project:member:1234567
| timestamp | 1474272114 |
project:member:1234566
| timestamp | 1474272113 |
project:member:1234565
| timestamp | 1474272115 |
那我的工作就簡單了:
首先我要取project:member的資料作為排序欄位,接著排序project:member:*(*為project:member的資料)底下的timestamp做順序,LIMIT是防止取不必要的資料下的限制,DESC則是從最大的開始,作用跟SQL的用法其實沒什麼差異
SORT project:member BY project:member:*->timestamp LIMIT 0 1 DESC
最後我可能會得到
1234565
那這個就是登入時間最大(最新)的使用者,再回去推算的話
HGET project:member:1234565 timestamp
恭喜,你得到它了!
總結
感謝各位收看完漏漏長的這篇(各種意味),接下來會在下一個章節介紹更多相關的應用,等哪天有空再補上吧!
